商務(wù)信息咨詢項(xiàng)目如何選擇 五大必知大數(shù)據(jù)處理框架技術(shù)對(duì)比分析

在當(dāng)今數(shù)據(jù)驅(qū)動(dòng)的商業(yè)環(huán)境中,商務(wù)信息咨詢項(xiàng)目能否高效處理海量數(shù)據(jù),直接決定了洞察的深度與決策的準(zhǔn)確性。面對(duì)眾多大數(shù)據(jù)處理框架技術(shù),如何選擇最適合自身項(xiàng)目的工具,成為咨詢團(tuán)隊(duì)的核心考量。本文將深入剖析五種主流大數(shù)據(jù)處理框架技術(shù),并從商務(wù)信息咨詢的應(yīng)用場(chǎng)景出發(fā),為您提供清晰的選型指南。
一、五大必知大數(shù)據(jù)處理框架技術(shù)概覽
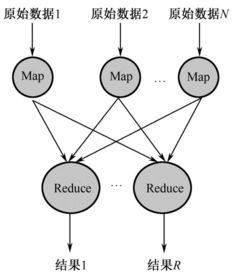
- Apache Hadoop:作為大數(shù)據(jù)領(lǐng)域的基石,Hadoop以其分布式文件系統(tǒng)(HDFS)和MapReduce計(jì)算模型聞名。它擅長(zhǎng)離線批處理,適合處理歷史業(yè)務(wù)數(shù)據(jù)、生成周期性報(bào)告,例如對(duì)過(guò)去一年的市場(chǎng)趨勢(shì)進(jìn)行宏觀分析。
- Apache Spark:憑借內(nèi)存計(jì)算優(yōu)勢(shì),Spark在批處理、流處理及機(jī)器學(xué)習(xí)等領(lǐng)域表現(xiàn)卓越。其速度遠(yuǎn)超Hadoop,適合需要實(shí)時(shí)或近實(shí)時(shí)分析的場(chǎng)景,如動(dòng)態(tài)監(jiān)測(cè)市場(chǎng)輿情、快速驗(yàn)證商業(yè)假設(shè)。
- Apache Flink:作為真正的流處理框架,F(xiàn)link支持事件驅(qū)動(dòng)型應(yīng)用,可實(shí)現(xiàn)極低延遲的數(shù)據(jù)處理。對(duì)于需要即時(shí)響應(yīng)的咨詢項(xiàng)目,如金融風(fēng)險(xiǎn)實(shí)時(shí)監(jiān)控或供應(yīng)鏈異常檢測(cè),F(xiàn)link是理想選擇。
- Apache Kafka:嚴(yán)格而言,Kafka是一個(gè)分布式事件流平臺(tái),常作為數(shù)據(jù)管道用于高吞吐量的實(shí)時(shí)數(shù)據(jù)集成。在咨詢項(xiàng)目中,它可用于連接多源數(shù)據(jù)(如CRM、社交媒體),確保數(shù)據(jù)流動(dòng)的可靠性與時(shí)效性。
- 云原生服務(wù)(如AWS EMR、Google BigQuery):各大云平臺(tái)提供的托管服務(wù),降低了運(yùn)維復(fù)雜度。對(duì)于資源有限或追求敏捷的咨詢團(tuán)隊(duì),這些服務(wù)能快速部署,靈活伸縮,適合短期或試點(diǎn)項(xiàng)目。
二、商務(wù)信息咨詢項(xiàng)目的選型關(guān)鍵因素
- 數(shù)據(jù)特性:
- 若數(shù)據(jù)以靜態(tài)歷史數(shù)據(jù)為主(如年度財(cái)務(wù)審計(jì)),Hadoop或Spark批處理模式更為經(jīng)濟(jì)。
- 若涉及高速流數(shù)據(jù)(如實(shí)時(shí)交易日志),應(yīng)優(yōu)先考慮Flink或Spark Streaming。
- 業(yè)務(wù)時(shí)效性要求:
- 對(duì)實(shí)時(shí)決策依賴強(qiáng)的項(xiàng)目(如競(jìng)爭(zhēng)情報(bào)動(dòng)態(tài)分析),需采用Flink或Kafka+Spark組合。
- 對(duì)時(shí)效要求寬松的深度分析(如行業(yè)長(zhǎng)期趨勢(shì)預(yù)測(cè)),Hadoop或Spark批處理已足夠。
- 團(tuán)隊(duì)技術(shù)能力:
- Hadoop生態(tài)成熟但學(xué)習(xí)曲線陡峭,適合有深厚技術(shù)積淀的團(tuán)隊(duì)。
- 云原生服務(wù)簡(jiǎn)化了運(yùn)維,更適合技術(shù)資源緊張或追求快速迭代的咨詢團(tuán)隊(duì)。
- 成本與可擴(kuò)展性:
- 自建集群(如Hadoop/Spark)前期投入大,但長(zhǎng)期定制性強(qiáng)。
- 云服務(wù)按需付費(fèi),適合業(yè)務(wù)量波動(dòng)大的咨詢項(xiàng)目,能有效控制成本。
三、實(shí)戰(zhàn)選型建議:匹配咨詢場(chǎng)景
- 場(chǎng)景一:市場(chǎng)進(jìn)入策略咨詢
需要整合多年行業(yè)數(shù)據(jù)與宏觀經(jīng)濟(jì)指標(biāo),進(jìn)行批量建模分析。推薦使用Spark,平衡處理效率與復(fù)雜性,并借助MLlib庫(kù)進(jìn)行預(yù)測(cè)分析。
- 場(chǎng)景二:客戶體驗(yàn)實(shí)時(shí)優(yōu)化咨詢
需處理來(lái)自網(wǎng)站、APP的實(shí)時(shí)用戶行為數(shù)據(jù),即時(shí)識(shí)別痛點(diǎn)。推薦采用Kafka收集數(shù)據(jù)流,由Flink進(jìn)行實(shí)時(shí)處理與告警,實(shí)現(xiàn)秒級(jí)洞察。
- 場(chǎng)景三:規(guī)模化數(shù)據(jù)平臺(tái)建設(shè)咨詢
為企業(yè)客戶設(shè)計(jì)長(zhǎng)期數(shù)據(jù)架構(gòu)時(shí),可結(jié)合Hadoop(存儲(chǔ)與批處理基礎(chǔ))與Spark(高性能計(jì)算),構(gòu)建混合框架以應(yīng)對(duì)多樣化需求。
- 場(chǎng)景四:敏捷型專項(xiàng)咨詢
項(xiàng)目周期短、需求多變,建議直接采用云服務(wù)(如BigQuery),無(wú)需基礎(chǔ)設(shè)施管理,專注分析邏輯與交付速度。
商務(wù)信息咨詢項(xiàng)目選擇大數(shù)據(jù)處理框架時(shí),應(yīng)摒棄“技術(shù)至上”思維,緊密圍繞業(yè)務(wù)目標(biāo)、數(shù)據(jù)特質(zhì)與資源約束進(jìn)行權(quán)衡。對(duì)于多數(shù)咨詢團(tuán)隊(duì),從Spark入手是一個(gè)穩(wěn)健的起點(diǎn),它在性能、生態(tài)與學(xué)習(xí)成本間取得了良好平衡。隨著項(xiàng)目深入,可逐步引入Kafka、Flink等組件構(gòu)建混合架構(gòu),最終形成貼合自身業(yè)務(wù)流的數(shù)據(jù)處理能力,從而在數(shù)據(jù)洪流中提煉出真正驅(qū)動(dòng)商業(yè)價(jià)值的決策智慧。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://m.jiedaxx.cn/product/45.html
更新時(shí)間:2026-01-06 13:45:38