大數據挖掘技術 互聯網金融風險控制的基石與引擎
隨著互聯網金融的迅猛發展,其便捷性與創新性為社會帶來了深刻的變革。與之相伴的是日益復雜的信用風險、欺詐風險、操作風險以及市場風險。傳統的風控模型依賴于有限的、結構化的歷史數據(如央行征信報告、財務報表),在應對海量、高頻、非結構化的互聯網交易行為時,往往顯得力不從心。在此背景下,大數據挖掘技術應運而生,成為驅動互聯網金融風險控制體系升級的核心力量。它通過對海量異構數據的深度處理與分析,實現了風險識別的前瞻性、精準性與動態化。
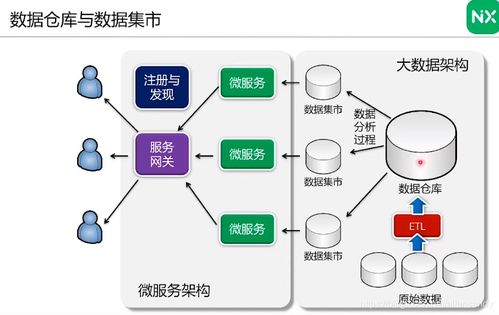
一、風險控制的數據基石:多維數據融合與處理
大數據挖掘助力風控的第一步,是構建全面、立體的數據基礎。這超越了傳統金融數據的范疇,廣泛涵蓋了:
- 用戶身份與信用數據:包括官方征信記錄、學歷、職業、社保繳納等強相關數據。
- 行為軌跡數據:用戶在互聯網上的瀏覽歷史、搜索記錄、App使用時長、地理位置信息等,這些數據能有效刻畫用戶的生活習慣與消費偏好。
- 社交網絡數據:從社交媒體、通訊錄、合作網絡中提取的關聯關系,用于評估個人的社會資本與影響力,識別欺詐團伙。
- 交易與消費數據:電商平臺的購物記錄、支付頻率、金額分布、充值行為等,直接反映用戶的消費能力與信用習慣。
- 設備與環境數據:申請設備信息(如設備ID、IP地址、操作系統)、網絡環境等,是識別機器攻擊、虛假申請的關鍵。
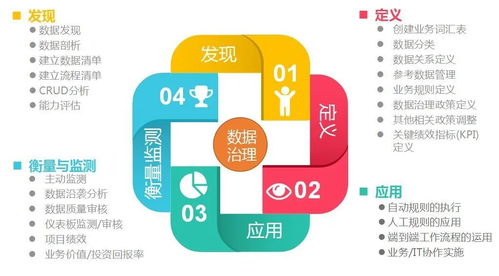
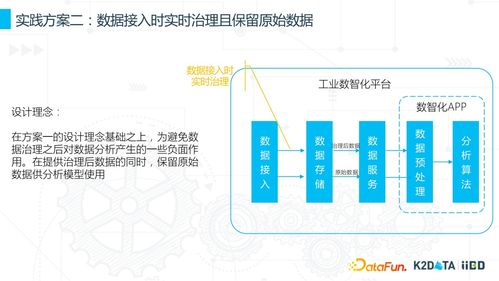
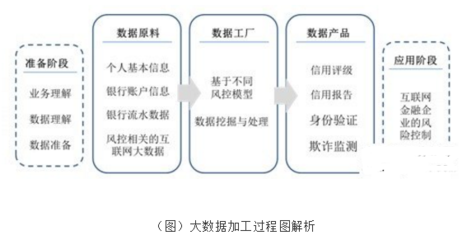
數據處理環節的核心任務,是將這些來源不一、格式各異的“原材料”進行采集、清洗、整合與標準化。例如,清洗掉無效、重復、矛盾的記錄;將非結構化的文本、圖像、日志轉化為可分析的量化特征;通過實體識別和關系圖譜技術,將分散的數據點連接成描述用戶全貌的“數字畫像”。這一過程為后續的深度挖掘奠定了堅實、高質量的數據基礎。
二、大數據挖掘的核心技術:從識別到預測
在高質量的數據湖基礎上,各類數據挖掘算法模型得以大顯身手:
- 機器學習與信用評分:運用邏輯回歸、隨機森林、梯度提升決策樹(如XGBoost、LightGBM)乃至深度學習模型,對數十萬甚至上百萬個特征變量進行訓練,構建新一代的信用評分卡。這些模型能夠自動發現復雜、非線性的風險模式,預測借款人違約的概率,其精準度遠超基于少數規則的傳統模型。
- 異常檢測與反欺詐:針對實時交易流,利用聚類分析(如孤立森林)、時序分析、圖計算等技術,實時檢測異常行為模式。例如,識別出短時間內同一設備或IP地址發起多筆申請的“羊毛黨”行為,或通過關系網絡分析發現具有欺詐特征的團伙聚集形態,實現欺詐交易的實時攔截。
- 自然語言處理與輿情監控:對新聞、財報、社交媒體評論、客戶服務對話進行情感分析和主題提取,可以提前感知宏觀經濟變化、行業動態或特定企業/個人的負面輿情,為市場風險和信用風險提供早期預警。
- 知識圖譜與關聯風險:構建包含個人、企業、地址、電話等實體及其關系的龐大知識圖譜。當評估一個新客戶時,系統能迅速探查其關聯實體(如聯系人、共同股東)是否存在高風險歷史,有效防控因關聯擔保、傳染效應導致的系統性風險。
三、動態閉環:從數據洞察到策略迭代
大數據挖掘驅動的風控體系是一個動態優化的閉環系統:
- 實時決策:在用戶申請貸款或進行交易的毫秒級時間內,系統調用實時數據流和模型,完成從數據輸入到風險評分與決策輸出的全過程。
- 監控與反饋:持續監控資產表現,將真實的違約、欺詐結果作為“標簽”反饋給模型。
- 模型迭代:基于新的反饋數據,定期或實時地重新訓練和優化模型,確保其能適應快速變化的市場環境和欺詐手段的演變。
四、挑戰與展望
盡管前景廣闊,大數據挖掘在互聯網金融風控中的應用也面臨挑戰:數據隱私與安全保護(需符合《個人信息保護法》等法規)、數據孤島導致的“信息煙囪”問題、復雜模型的可解釋性要求,以及應對“對抗性攻擊”(欺詐者故意調整行為以欺騙模型)的能力。
隨著聯邦學習、隱私計算等技術的發展,有望在保護數據隱私的前提下實現跨機構的數據價值融合;可解釋人工智能(XAI)將提升復雜模型的透明度和可信度;而圖神經網絡等前沿技術將進一步強化對復雜關聯風險的洞察力。
數據處理是大數據挖掘的起點,也是其價值得以發揮的保障。在互聯網金融風險控制這場沒有硝煙的戰爭中,大數據挖掘通過將海量、雜亂的數據轉化為精準、前瞻的風險洞察,正在重塑風控的邊界與效能。它不再僅僅是事后的“防火墻”,更是事前的“預警雷達”和事中的“智能指揮官”,為互聯網金融的健康、可持續發展提供了不可或缺的技術引擎。
如若轉載,請注明出處:http://m.jiedaxx.cn/product/35.html
更新時間:2026-01-06 13:57:17